Shared Task on Offensive Language Detection
Offensive speech (vulgar or targeted offense), as an expression of heightened polarization and discourse in society, has been on the rise. This is due in part to the large adoption of social media platforms that allow for greater polarization. The shared task attempts to detect such speech in the realm of Arabic social media.
In subtask A, we will use the SemEval 2020 Arabic offensive language dataset (OffensEval2020, Subtask A), which contains 10,000 tweets that were manually annotated for offensiveness (labels are: OFF or NOT_OFF). Offensive tweets contain explicit or implicit insults or attacks against other people, or inappropriate language. We will use the same splits of OffensEval2020 for train (70% of all tweets), dev (10%), and test (20%).
Example: يا مقرف يا جبان للأسف هذه تسمى خسة من شخص أحمق
In addition to Subtask A, there will be another subtask for detecting Hate Speech (Subtask B) for the whole dataset. If a tweet has insults or threats targeting a group based on their nationality, ethnicity, gender, political or sport affiliation, religious belief, or other common characteristics, this is considered as Hate Speech (labels are: HS or NOT_HS). Subtasks A and B share the same splits.
Example: الله يقلعكم يالبدو يا مجرمين يا خراب المجتمعات
Subtask B is more challenging than Subtask A as 5% only of the tweets are labeled as hate speech while 19% of the tweets are labeled as offensive. We encourage submissions to both subtasks.
Note: User mentions are replaced with @USER, URLs are replaced with URL, and empty lines in original tweets are replaced with <LF>.
The purpose of this shared task is to intensify research on the identification of offensive content and hate speech in Arabic language Twitter posts. One goal of the workshop is to define shared challenges using this dataset. We encourage submissions describing experiments for research tasks on the dataset.
Data:
The data is retrieved from Twitter and distributed in tab separated format as follows:
tweet_text \t OFF (or NOT_OFF) \t HS (or NOT_HS)\n
Ex: @USER اخرص يا أعرابي يا وقح فلن تعدو قدرك يا سافل \t OFF \t HS \n
Download training/dev data from here: Training Set, Development Set.
Evaluation Criteria:
Classification systems will be evaluated using the macro-averaged F1-score for Subtasks A and B.
Now gold-standard labels for test data can be downloaded from here: Task A, Task B.
Submission Format:
Classifications of test and dev datasets (labels only) should be submitted as separate files in the following format with a label for each corresponding tweet (i.e. the label in line x in the submission file corresponds to the tweet in line x in the test file):
For Subtask A:
OFF (or NOT_OFF)\n
For Subtask B:
HS (or NOT_HS)\n
Participants can submit up to two system results (primary submission for best result, and a secondary submission for the 2nd best result).
Official results will consider primary submissions for ranking different teams, and results of secondary submissions will be reported for guidance. All participants are required to report on the development and test sets in their papers.
Sumbission filename should be in the following format:
ParticipantName_Subtask<A/B>_<test/dev>_<1/2>.zip (a plain .txt file inside each .zip file)
Ex: QCRI_SubtaskA_test_1.zip (the best results for Subtask A for test dataset from QCRI team)
Ex: KSU_SubtaskB_dev_2.zip (the 2nd best results for Subtask B for dev dataset from KSU team)
The shared task is hosted on CODALAB using the following links for each subtask:
Subtask A: CODALAB link.
Subtask B: CODALAB link.
Test Set: is now released on CODALAB. Please find get it from there.
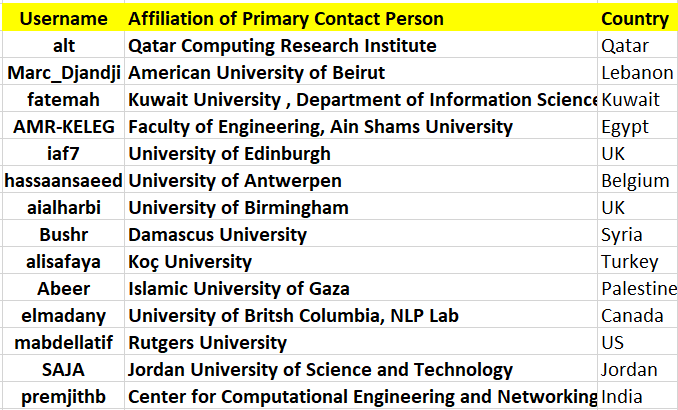
Contact:
For any questions related to the shared task, please contact the organizers using this email address: hmubarak@hbku.edu.qa
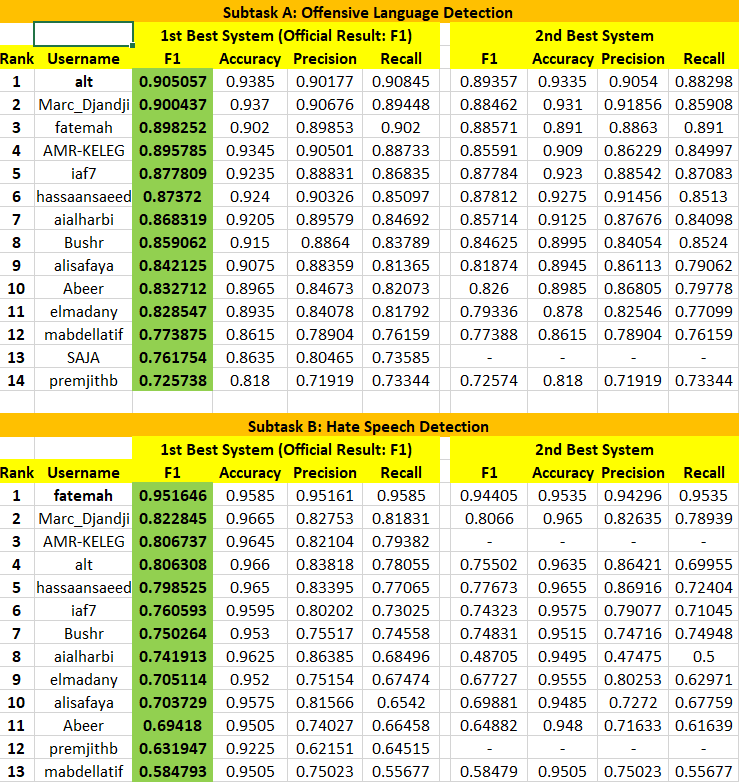
Results:
Please find below the results of the partipant teams sorted by F1-score.
Teams: